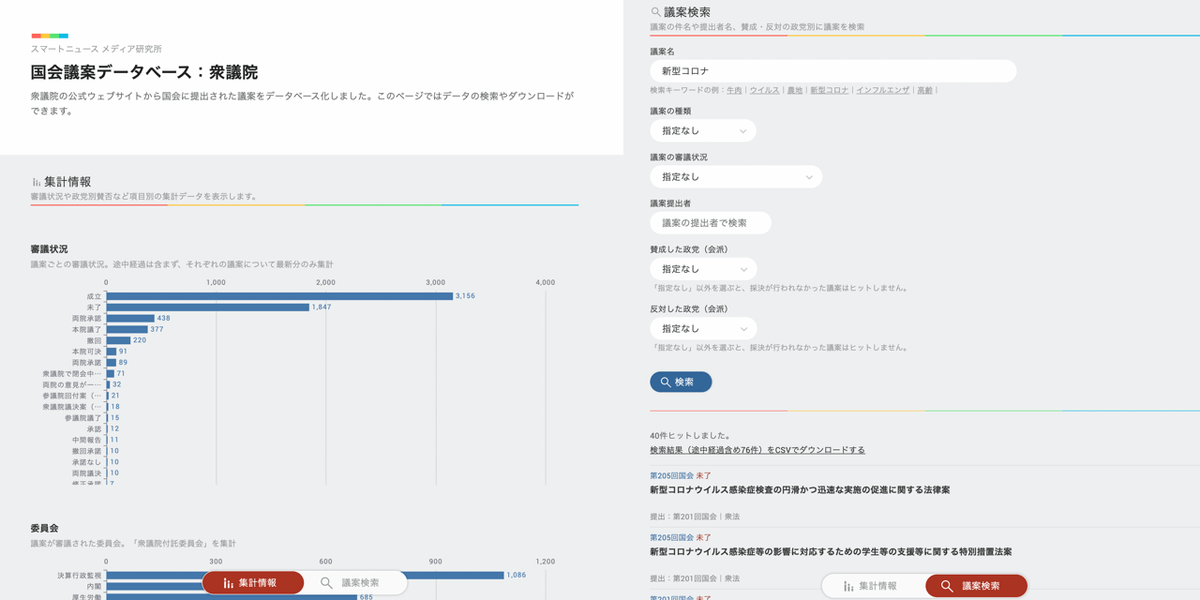
スマートニュース メディア研究所では、7月1日に「国会議案データベース」を公開しました。衆議院および参議院の公式ウェブサイトから計約1万8000件以上の法律案や予算案を取得し、機械可読な形で整理されたデータベースとしてGitHubで無償提供するものです。参議院については、会派や議員、質問主意書のデータも同時に公開しました。
国会議案データベース(GitHub)
衆議院 https://github.com/smartnews-smri/house-of-representatives
参議院 https://github.com/smartnews-smri/house-of-councillors
国会議案データベース・閲覧用ページ
衆議院 https://smartnews-smri.github.io/house-of-representatives/
参議院 https://smartnews-smri.github.io/house-of-councillors/
私(荻原)の所属するメディア研究所はスマートニュース株式会社のシンクタンクです。ニュースやメディアと社会との関わりや公益性について、中長期的な視点からの研究や提言などを行っており、昨年10月にはデータ報道などの支援を目的として市区町村や選挙区の境界データの無償公開などを行いました。今回は参議院選挙が近づいていたこともあり、報道や研究などに役立てていただくため、前回に引き続き誰でも無償で使える形でデータの公開を行いました。
基本的なデータの内容は先日メディア研究所のウェブサイトに掲載した記事にて概観しましたが、今回は「ワードクラウド」と呼ばれる可視化手法を使って実際にデータを眺めてみると同時に、ワードクラウドの作り方を解説します。
ワードクラウドとは何か
ワードクラウドとは、大量のテキストを単語に分け、登場回数などをもとにサイズや色を調整し、画像として表現するデータ可視化手法のひとつです。単語が集まった状態が雲(Cloud)のように見えるのでワードクラウド(Word cloud)と呼ばれます。たとえば会議の議事録やアンケートの自由回答など、すべて読もうとすると時間がかかる長文のテキストであっても、大まかにどのような内容を表しているかを1枚の画像で簡潔に表現できます。
最近は日本のメディアでもワードクラウドを活用するケースが増えています。先日の参議院議員選挙でも、候補者や現職議員の行った演説の内容をワードクラウドで表現する記事が数多く見られました。たとえば河北新報オンラインニュースでは、公示日における宮城選挙区の候補者の演説内容をワードクラウドで表現しています。

記事の後半で実際のデータをもとにワードクラウドを作る方法を解説しています。同じような画像を再現したい方は参考にしてください。
法律案の変遷をワードクラウドで見る
さて、このワードクラウドを国会議案データベースに当てはめて各年代の議案を見てみます。提出される議案の内容は、おそらくその当時の世相を反映したものとなっているはずです。毎年ほぼ同じ形式である予算案やNHK決算などは除き、法律案(衆法、参法、閣法)を対象としてワードクラウドを作ってみます。
まず直近の約3年間(第201回国会以降)に提出された法律案から見てみましょう。単語の登場回数をもとに、表示する大きさや色を決めています。色調や表示設定などに関しても後半で詳しく説明します。

新型コロナが猛威を奮った時期の国会であるため、「コロナ」「ウイルス」「感染」といった単語が最も大きく表示されています。一方で「措置」「推進」「給付」「支給」「支援」といった文字も目立ちます。新型コロナ禍によって経済的に困窮した人を支援する制度が議論されていることがわかります。
この時期に成立した法案には、たとえば2020年6月に全会一致で可決した「新型コロナウイルス感染症等の影響に対応するための雇用保険法の臨時特例等に関する法律案」があります。新型コロナの影響で休業を余儀なくされたにもかかわらず、会社から休業手当を受け取れない人たちを支援する「新型コロナウイルス感染症対応休業支援金・給付金」が盛り込まれました。
次に約10年前、2011年から2013年にかけてのデータを見てみます。

東日本大震災の直後ですが「震災」「被災」といった語は比較的小さく、「地方」「地域」などの単語が多いようです。震災直後に成立した「国民生活等の混乱を回避するための地方税法の一部を改正する法律案」のように、震災による影響を考慮した特例措置などを定める法案が多かったためと思われます。
続いて、記録されている最も古いデータを見てみます。衆議院の議案データは1998年の第142回国会から存在します。ここから約5年間、第155回国会までのデータをワードクラウドにしてみましょう。

「独立行政法人」に関する単語が最も目立つ結果になりました。1990年代後半には行政改革の一環として、国立科学博物館や種苗管理センターといった公的な業務を運営する機関が中央省庁から独立して法人化されることになりました。その際、1999年の第146回国会にて、各機関の目的や業務範囲を定める法律案が数多く成立したため、このキーワードが強く表示されることになったと思われます。
Pythonを使ってワードクラウドを作る
続いて、上記で紹介したようなワードクラウドを実際に作る方法を解説します。文章からワードクラウドを生成するツールは複数の企業や団体が提供していますが、今回は細かな設定を自分で調整するため、Pythonを使ってワードクラウドの画像生成を行います。以下、データの取得からワードクラウド画像の生成までを順番に追っていきます。
なお、実行環境はGoogleが提供するPythonの実行環境であるGoogle Colab(Colaboratory)を使っています。本稿の趣旨からは外れるので詳細な解説は行いませんが、自分で実行環境を整えなくてもPythonを実行できる便利なサービスですので、興味のある方は自分でも再現してみてください。
まず、今回使ったコードの全体像を掲載します。大まかに言うと、
(1)議案のCSVファイルを読み込んで各種条件で絞り込んで変数にまとめ、
(2)形態素解析(文章を「吾輩/は/猫/で/ある」のように単語に分け、動詞や名詞などの品詞に分解)を行うライブラリ「MeCab」を使って品詞を分解しつつ名詞のみに絞り込み、
(3)ワードクラウド画像を生成するライブラリ「WordCloud」を使って画像を生成・保存します。
ソースコード全文はこちらで公開しています。
前準備
あらかじめ、フォントファイルをGoogle Colab(またはお好きな環境)にアップロードしておきます。WordCloudのデフォルトフォントでは日本語を表示することができないため、日本語に対応しているフォントを使いましょう。お好きなフォントを指定して大丈夫ですが、漢字が多い内容となるため、ゴシック体よりも明朝体、それもウェイト(文字幅)が太めのフォントが適しているだろうと考えて「ZEN アンチック」というフォントを使いました。Google Fontsよりダウンロードすることが可能です。ダウンロードした「ZenAntique-Regular.ttf」ファイルをcontentフォルダ直下にアップロードしておきます。もし別の配置で使う場合は、コード50行目のフォント指定を変えてください。
1〜6行目
文字コードの指定とライブラリの読み込みです。外部ファイル(ここでは国会議案のCSVファイル)を読み込むためのrequests、MeCab、ワードクラウドを生成するWordCloudの3つを使っています。
8〜11行目
GitHubリポジトリにて公開されている国会議案のCSVファイルを読み込んで、1行ごとの配列(csv_rows)に分けています。
13〜26行目
1行ごとに議案データを読み込み、国会回次や議案の種類で絞り込んでいます。今回はワードクラウド生成で使った最初の画像(新型コロナ禍での提出法案)を再現するため、第201〜208回国会の衆法・参法・閣法に絞ります。
28〜31行目
MeCabを使って形態素解析したデータを単語ごとに分解し、parsed_rowsに格納しています。parsed_rowsの1要素=1単語はこのようになります:
['日本', 'ニッポン', 'ニッポン', '日本', '名詞-固有名詞-地名-国', '', '', '3']
33〜46行目
単語ごとにEOS(End Of Sentence=文末を示す記号)を除外します。また今回は「する」「の」といった動詞や助詞は省きたいので、名詞だけに限定します。絞り込まれた単語をresultに格納していきます。resultは「保険 法 臨時 特例 法律 一部 改正 法律 案 時間」のように単語が半角スペースで区切られた形になります。
48〜57行目
WordCloudを使ってワードクラウド画像を生成します。font_pathは単語に使うフォントファイルです。先ほどアップロードしたフォントファイルを指定します。width / heightはそれぞれ画像の横幅・縦幅を示します。prefer_horizontalはどの程度単語を横書きにするかを表します。1だとすべての単語が横向きに、0だと縦向きになります。縦向きの単語は文字が90度横に倒れてしまうので、今回はすべて横向きとしました。
background_colorは背景色を指定します。カラーコードの他に色の名前(「white」など)でも指定できます。もちろんどのような色でも構いませんが、私はダークトーンの色調をよく使うので暗い紺色(#061a2b)としました(ちなみに社内の同僚からは「サイバーパンクな感じ」と感想をもらいました)。
colormapは文字の配色パターンを示しています。今回使った「GnBu」は小文字が明るい緑色、大きな文字は暗い青色で表すパターンです。WordCloudのカラーマップは、同じくPythonのグラフ描画ライブラリである「Matplotlib」に準拠しています。今回は3つのワードクラウド画像を作成しましたが、視覚的にも少しずつ差をつけるためにカラーマップを変えました。1枚目は「GnBu」、2枚目は明るい黄色からオレンジを経て暗いブラウンに至る「YlOrBr」、3枚目は1枚目と対照的に明るい青色から暗い緑色である「BuGn」を使っています。
stopwordsとはワードクラウドの対象外とする単語です。たとえば国会議案でいうと「法律」「一部」「改正」といった単語は、議案の内容にかかわらず数多く登場します。今回は時期によって法律案に使われる単語がどう異なるかを見たいので、これらの単語は除いた方がよいと考え、ストップワードを設定しています。
これらの設定でワードクラウド画像を生成(57行目)し、最後に60行目でファイル名を指定して保存します。なお、WordCloudではすべての設定を同じにしても単語の位置や色が若干異なる場合があります。そのため上記に掲載したものとまったく同じ画像は作れないかもしれませんが、設定が同じであれば全体的な配置や色調はほぼ同じものが出来上がるはずです。
以上、国会議案データをワードクラウドで表現したサンプルと作り方を解説しました。コードを読んでいただくとわかるように、今回は形態素解析、日本語フォント、ワードクラウド生成、そして国会議案データベース、いずれもオープンソースで無償提供されているものを使いました。「コードでインフォグラフィックを作成する」と聞くと非常に難しいものに感じてしまいますが、実際にはこれらのツール・サービス開発者の努力によって、今までよりもコードで何かを作るハードルは低くなっています。ぜひ皆さんも自分の興味あるデータや可視化手法を使って、面白いコンテンツを作っていただければと思います。
著者紹介

荻原 和樹(おぎわら・かずき)
スマートニュース メディア研究所 シニア アソシエイト
前職では東洋経済オンライン編集部などに所属し、データ可視化を活用した報道コンテンツの開発、デザイン、記事執筆を行う。2021年スマートニュースに入社。メディア研究所ではデータ可視化やデータ報道に関する情報発信、アドバイザリーなどを行う。